什么是 exemplar
在可观测领域,通常把一个系统为了完成某个功能,所发起的相关动作称之为事件。比如,对于「电商网站」系统的「访问产品详情页」的功能,背后的实现包括了鉴权,访问缓存,访问数据库等等事件。
为了能够更好的对系统进行监控,可观测领域沉淀出三种经典的可观测数据类型,并且把他们叫做可观测领域的三根支柱(pillar)
- log: 用于记录完成某个动作的详细内容。
- trace: 用于记录完成某个功能的所有动作,以及每个动作的基础信息,比如耗时,是否成功等等。
- metric: 用于统计所有同类动作的整体表现,比如平均耗时
但是在工作中我们经常遇到的一个场景是:当系统的某个核心 metric 发生了抖动时,我们仅仅通过 metric 上的信息,是很难确认到底是哪些具体的请求导致了这种波动,所以就需要再通过 trace 系统去大海捞针,捞出那些异常的请求再进行分析,整体是非常低效的。
所以为了解决这个问题,exemplar 技术诞生了。它为 metric 和 trace 之间建立起了一座桥梁,使用户在遇到上面的问题时,可以直接一键跳转到导致 metric 波动的具体请求的 trace 详情中,大幅提升排障的速度和精度。这项技术也是由 Google 发起,并且也其公司得到了广泛使用。详细介绍可以看这篇视频。
exemplar 的定义
因为 exemplar 是 metric 和 trace 之间的桥梁,所以为了达成这个效果,需要再 metric 数据上附带可以推导相关 trace 的信息,最常用的信息就是具体的 trace id。
从 OpenMetric 官方文档给出的示例就有最直观的体现
# TYPE foo histogram
foo_bucket{le="0.01"} 0
foo_bucket{le="0.1"} 8 # {} 0.054
foo_bucket{le="1"} 11 # {trace_id="KOO5S4vxi0o"} 0.67
foo_bucket{le="10"} 17 # {trace_id="oHg5SJYRHA0"} 9.8 1520879607.789
foo_bucket{le="+Inf"} 17
foo_count 17
foo_sum 324789.3
foo_created 1520430000.123
从上面的数据示例可见 exemplar 信息既可以只包含 trace id 和具体的 trace 对应的值,比如
foo_bucket{le="1"} 11 # {trace_id="KOO5S4vxi0o"} 0.67
也可以再进一步包含 trace 对应的 timestamp,比如
foo_bucket{le="10"} 17 # {trace_id="oHg5SJYRHA0"} 9.8 1520879607.789
exemplar 使用体验
目前 Prometheus,Grafana,Tempo 等开源产品都已经实现并且兼容 exemplar 能力。我通过一个简单已经开启 exemplar 的实例来展示一下 exemplar 的基本使用体验。
例子中我构造一个非常简单的 http server,来模拟最开始我提到的那个日常的排障场景。
代码位于项目中
https://github.com/fatsheep9146/awesome-observability/tree/main/demos/exemplar-simple-demo
整个 demo 环境,包括如下几个服务
- http server 服务:一个简单的 http server,埋点了 trace,metric 相关信息,并且使用了 exemplar 特性
- http client 服务:周期性发起 http 请求访问 http server 服务
- tempo 服务:用于接收 http server,http client 发出的 trace 信息
- prometheus 服务:用于抓取 http server 暴露的 metric
- grafana 服务:以 tempo,prometheus 服务为 datasource,提供 dashboard
可以通过如下命令,启动整个 demo 环境
docker compose up --no-build -d
启动后,即可通过 grafana dashboard
http://127.0.0.1:3000/d/fOpOPcO4k/demo-server?orgId=1&from=now-5m&to=now
去查看一个已经绘制好的 http server 的 dashboard,
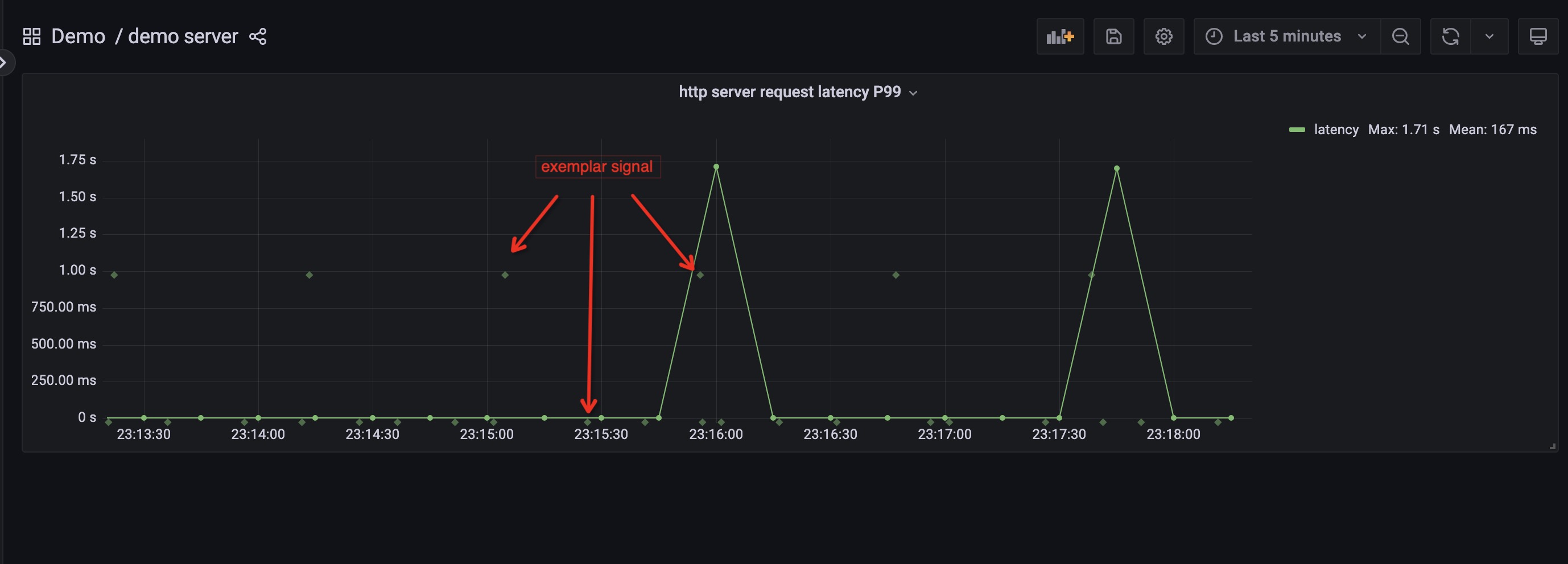
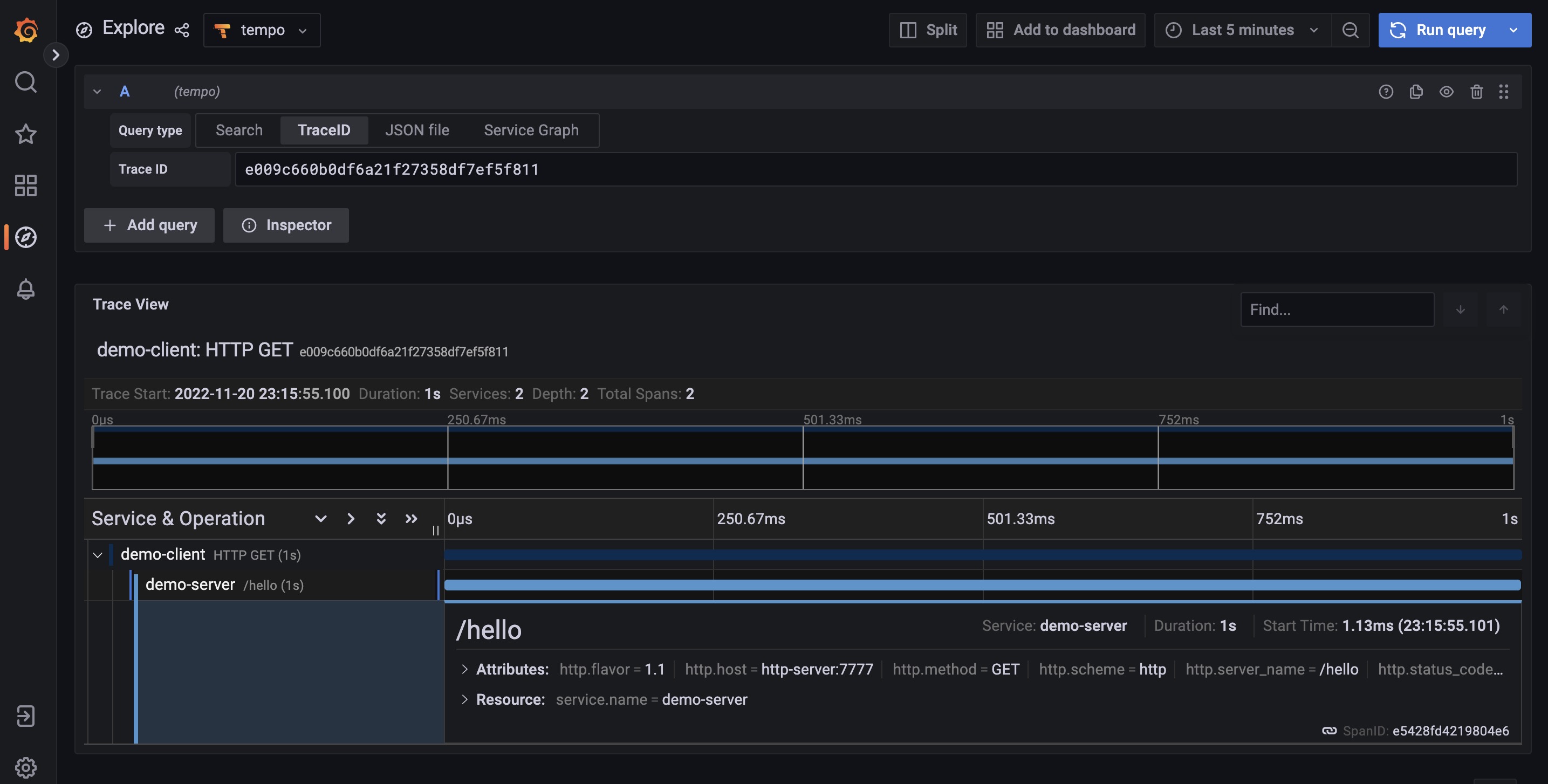
在 dashboard 中,我们可以看到展示的是 http server 响应请求延时的 P99 值,并且在图中除了包括表示趋势变化的指标线以外,在线的周围还包括了一些散点,这些点其实表示的就是在这个时间线上出现过的 exemplar 信号。
将光标移动到一个 P99 值显著比其他点的要高的 exemplar 光标上时,grafana 就会弹出一个提示窗口,其中既包含了这个 exemplar 信号的详细信息,比如这个信号对应的 trace id,具体的延时等,还包括了一个可以基于这个 trace id 进行跳转的按钮。
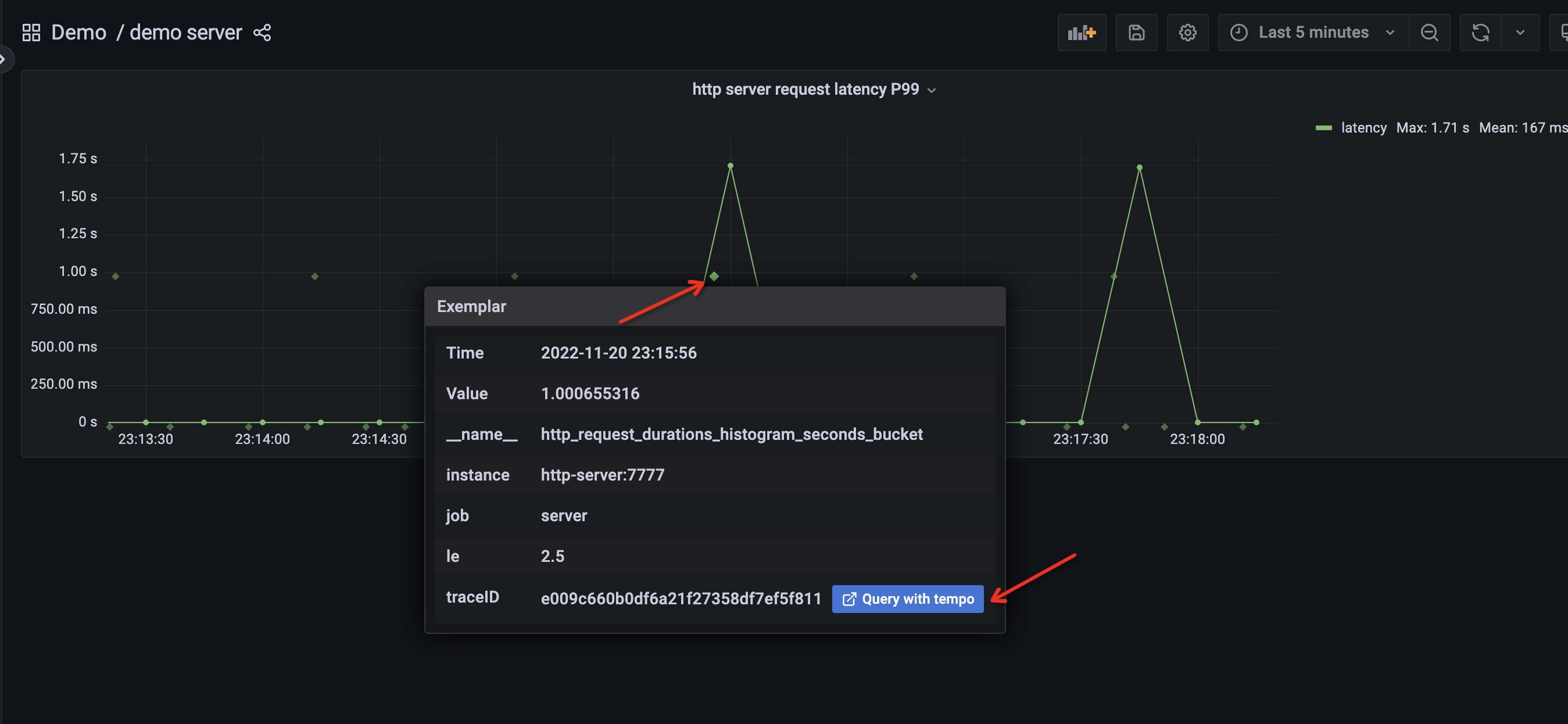
从这个按钮点击进去之后,我们就可以看到这个 trace 的详细视图了。我们就可以基于这个视图从 trace 的视角去分析异常的原因。