2022 KubeCon 北美站于十月在底特律召开。可观测性(observability)作为一个热门主题,有多达 7 个 talk。
最近 kubecon 官方也把所有 talk 的录像都放出了,所以在这篇文章主要就是记录了一下我对这几个 talk 录像的观后感,以及引发的思考。
Talk 1: Customer Centric Observability: How Intuit Reduced Time To Detect Customer Impact From 30+ Minutes To Under 3 Minutes.
直译:以客户为核心的可观测: Intuit 公司是如何将对客户体验有损情况的发现速度从30分钟+提速到3分钟
Intuit 公司是一家以财务软件为主的大型 SAAS 公司。并且根据讲者的介绍,所有 SAAS 子产品都是在 Intuit 的5大基础平台之上所构建出来的。
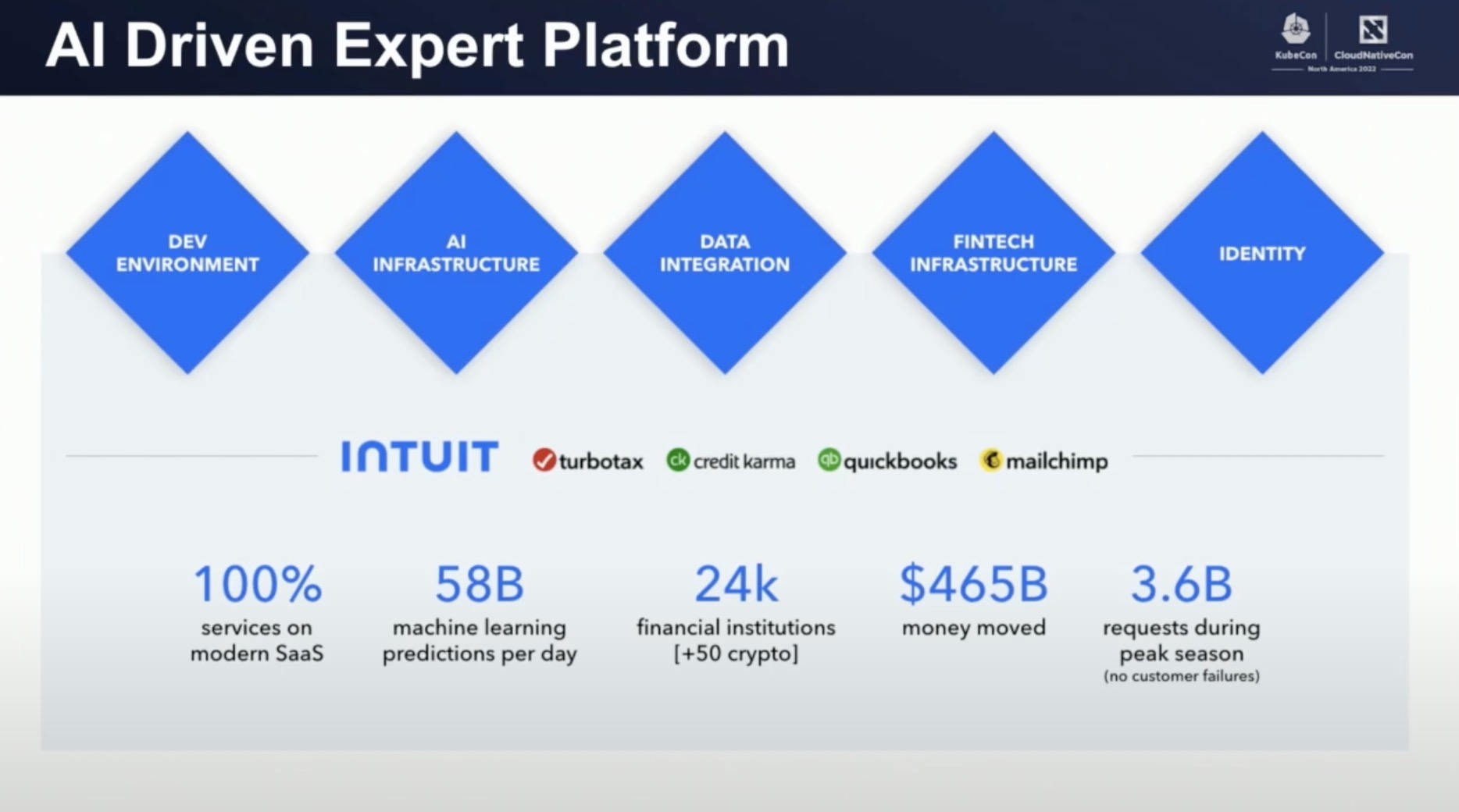
讲者所在的部门,就是5个基础平台之一,开发平台。他们的目标就是:让研发人员更快更稳的进行开发迭代。从他所提供的平台规模数据来看(百万核,2000+的微服务,900+团队,6000+开发人员,16000+命名空间),要达成这个目标是非常有挑战的。其中,可观测性建设就是挑战之一。
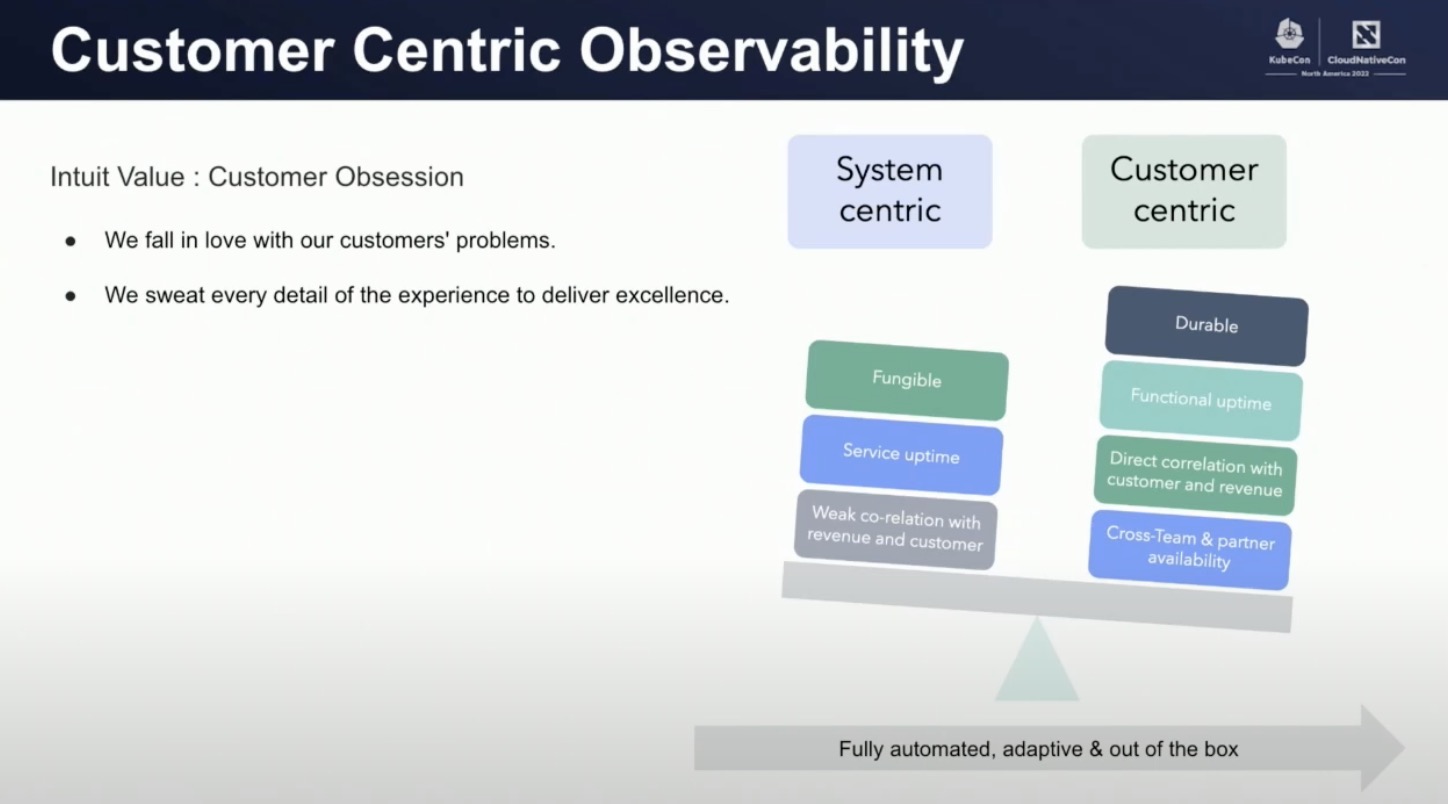
讲者总结了在优化前,他们的可观测能力建设的思路是 “以服务为中心进行监控” (system centric monitoring),而这种思路也确实让他们遇到很多问题。
- 缺乏对客户影响面的理解
- MTTD 超过 30min
- 难以定位根因
- 更高额的可观测成本
- 不能充分利用可观测数据的价值
所以他们重新思考,从用户体验出发,采取以用户为核心的新思路进行可观测性建设,从而能更加直观的判断对于用户体验的影响面。当然,并不是要把产品中用户每一个可能的动作都视作为核心用户动作,他们为核心用户动作也制定了自己的定义:只有真正会带来 “价值” 的动作才是核心用户动作。
以这个新的思想为基础,他们建设了一个 FCI(Failed Customer Interactions) 平台,专注于监测核心用户动作的可用性,整体架构如下
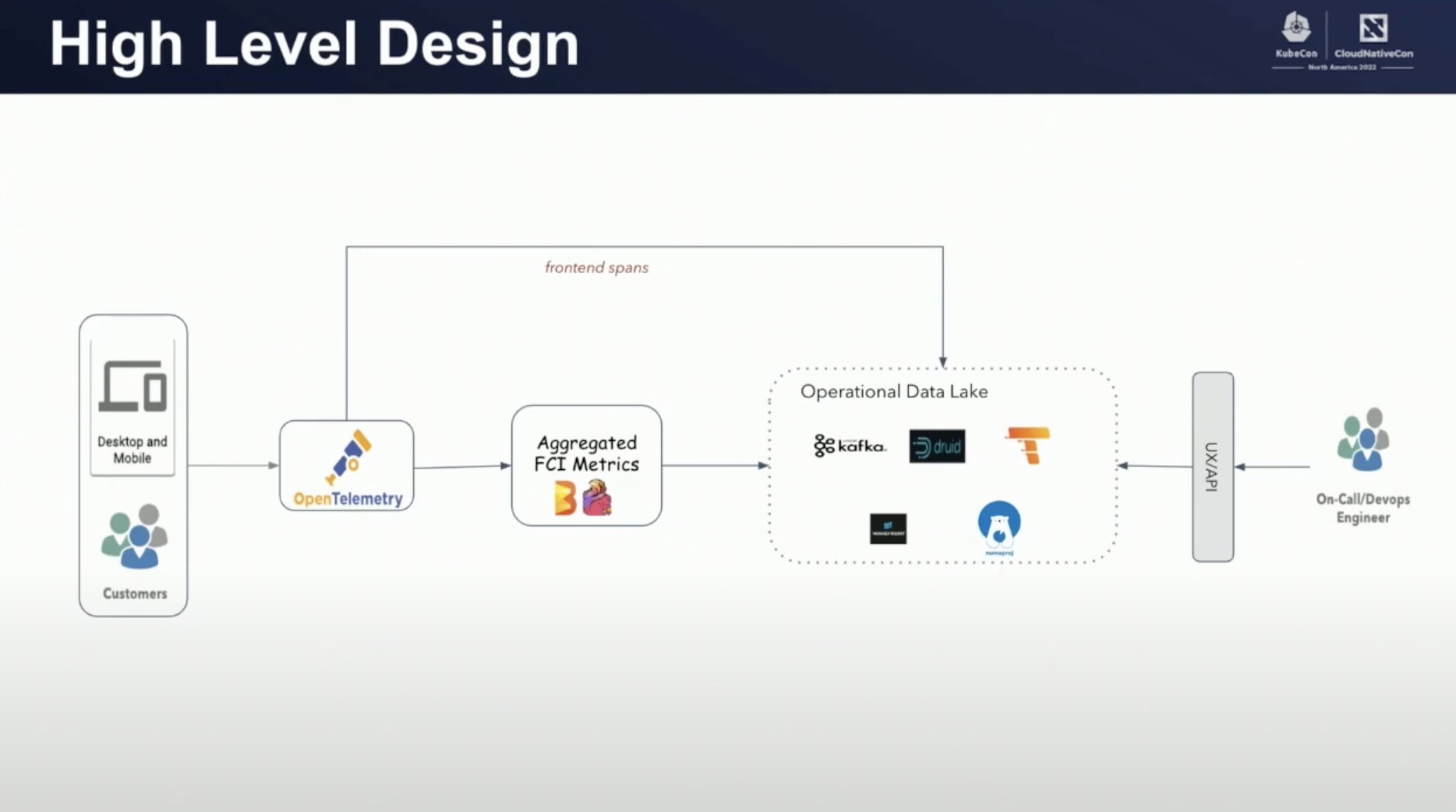
首先平台提供了一个基于 OpenTelemtry 的监控埋点库。所有 app 或者浏览器都通过这套埋点库进行 trace 数据埋点。当终端用户进行操作时,所有重点操作都会以 span 的形式上传到 FCI 平台,并且会通过两种方式进行二次处理。
- 一方面会基于原始 Span 数据计算出统计型的 Metric 数据,再投送到基于 Druid 的数据湖中。
- 另一方面会直接把 Span 数据直接存储到 tempo 服务中。
有了这两部分基础数据后,Intuit 是怎样做到提升 MTTD 从30分钟到3分钟的效果的呢?主要做了两方面的事情
- 采用优化算法快速确认影响客户的范围
数据湖中的时序数据,通常是包含了多维度标签的原始数据,比如用户的ID,用户发起的动作类型。想要快速从这些原子数据中快速统计出有多少客户的某种动作收到的影响,需要执行 Count Distinct 的查询。但是这种查询,在大规模的数据量下,执行效率低并且对内存开销大。
所以讲者通过 Apache Datasketches 大数据算法库中的 HyperLogLog 算法,可以非常快速,并且以非常低的内存开销,完成 Count Distinct 类型的查询。从而可以快速确认问题影响面(当前有多大比重的客户的某个客户功能失败),并且可以根据影响面进行报警。

- 采用机器学习进行异常信息降噪
Intuit 团队通过实际的数据分析发现,报错是时时刻刻都在发生的,尤其是移动端,浏览器端等复杂的前端环境。所以如果无法做到很好的降噪,就无法做到快速发现真实的问题。所以 Intuit 团队开发并且开源了名为 NumaProj 的机器学习平台,以数据湖中的多种时序数据指标为输入进行训练,最终推演出一个叫做 anomaly score 的值,只有这个值达到一定范围才是真正的异常出现,即可进行报警。

我的思考:
- 随着 opentelemetry 标准协议的引入,任何以该协议作为基础建设的工具或者产品,都可以快速以开源推向社区,并且被以很低的接入成本进行体验和论证。就像 talk 中提到的 NumaProj。相比于以前,换个产品就要兼容一套协议的时代,opentelemetry 可以极大提升可观测领域的创新速度。
Talk 2: SLO-Based Observability For All Kubernetes Cluster Components
直译:对所有 kubernetes 组件进行基于 SLO 可观测性建设。
在这个 talk 中,讲者介绍了一个叫做 Pyrra 的开源项目,该项目的目标是构造一个,以 Prometheus 为数据源,以更低成本对 SLO 进行管理的平台。
SLO 是 SRE 发现系统稳定性隐患的重要抓手,也是驱动系统稳定性提升的数据支撑。但是对于大多数用户来说,如何管理自己的 SLO,甚至是如何定义一个 SLO 都是一个不容易的工作。讲者也在 talk 中特别提到,在他们发起这个项目之前,特意找了一些客户(特别是各种公司的 SRE 团队)做了一些调研和咨询,收集到了一些在使用 SLO 遇到的常见问题。

在这个背景下,Pyrra 项目也诞生了。作为一个 SLO 管理平台,他的架构还是比较简洁的,就是一个前端 UI 和后端 server 的标准架构,当然还依赖于一个 prometheus 作为数据源。部署方式支持 kubernetes, docker 和 systemd 三种方式。
而这套平台为用户提供的能力是
- 快速,灵活的创建 SLO 规则
- 功能齐全,开箱即用基于 UI 的 SLO 管理控制台
SLO 规则的创建更新是基于 CRD 的,平台定义了用于描述一个 SLO 的 CRD ServiceLevelObjective,其中包括描述一个 SLO 需要的所有基本的信息。
apiVersion: pyrra.dev/v1alpha1
kind: ServiceLevelObjective
metadata:
labels:
prometheus: k8s
role: alert-rules
name: apiserver-read-resource-request-latency
namespace: monitoring
spec:
description: ""
indicator:
latency:
success:
metric: apiserver_request_duration_seconds_bucket{job="apiserver",scope=~"resource|",verb=~"LIST|GET",le="1"}
total:
metric: apiserver_request_duration_seconds_count{job="apiserver",scope=~"resource|",verb=~"LIST|GET"}
target: "99"
window: 2w
- description: SLO 的描述
- indicator: SLO 的基本类型,和获取 SLO 数据的查询语句
- target: SLO 的目标
- window: 统计时间窗口
当 SLO 创建完成后,Pyrra 后台就会将这些 SLO 以 recording rule 的形式,下发到 Prometheus 服务中。并且也顺便为这些 recording rule 设置对应的报警 alerting rules。
在 SLO 管理控制台上,可以看到所有创建好的 SLO,以及每个 SLO 的概况
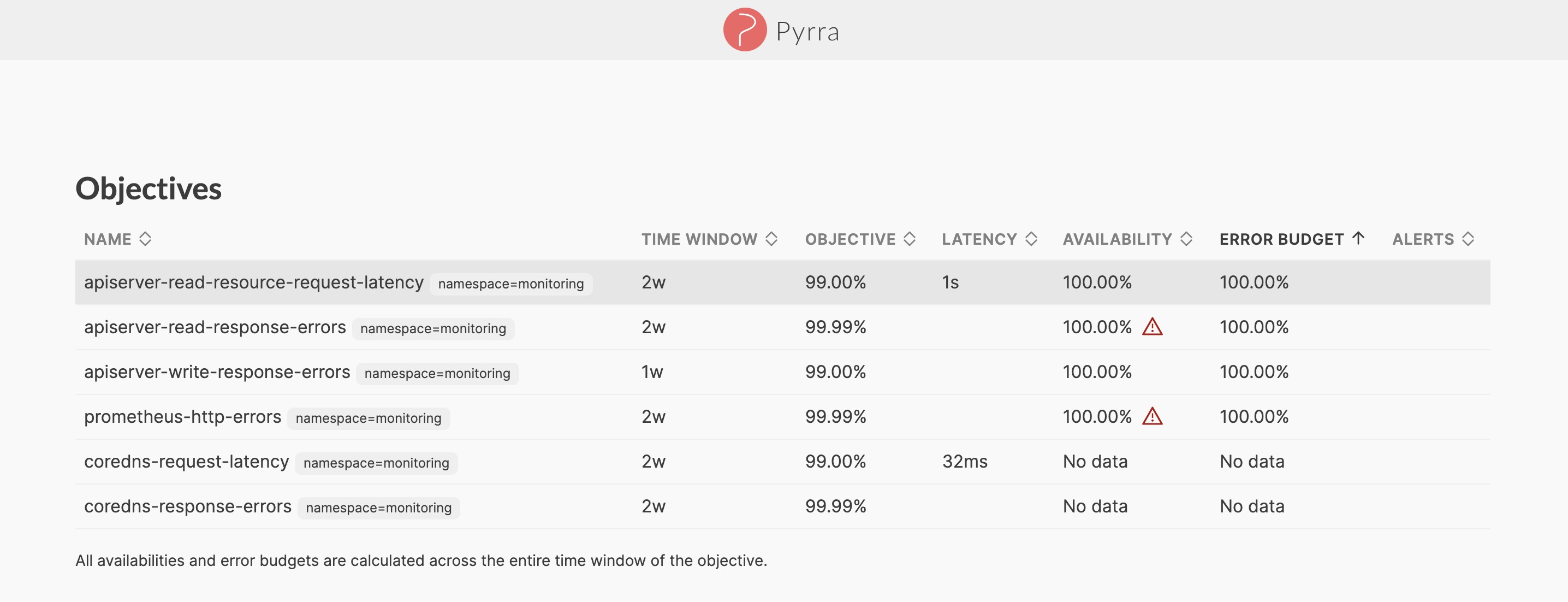
针对每个 SLO 都有一个详情页进一步查看 SLO 最近一段时间的变化情况,报警历史
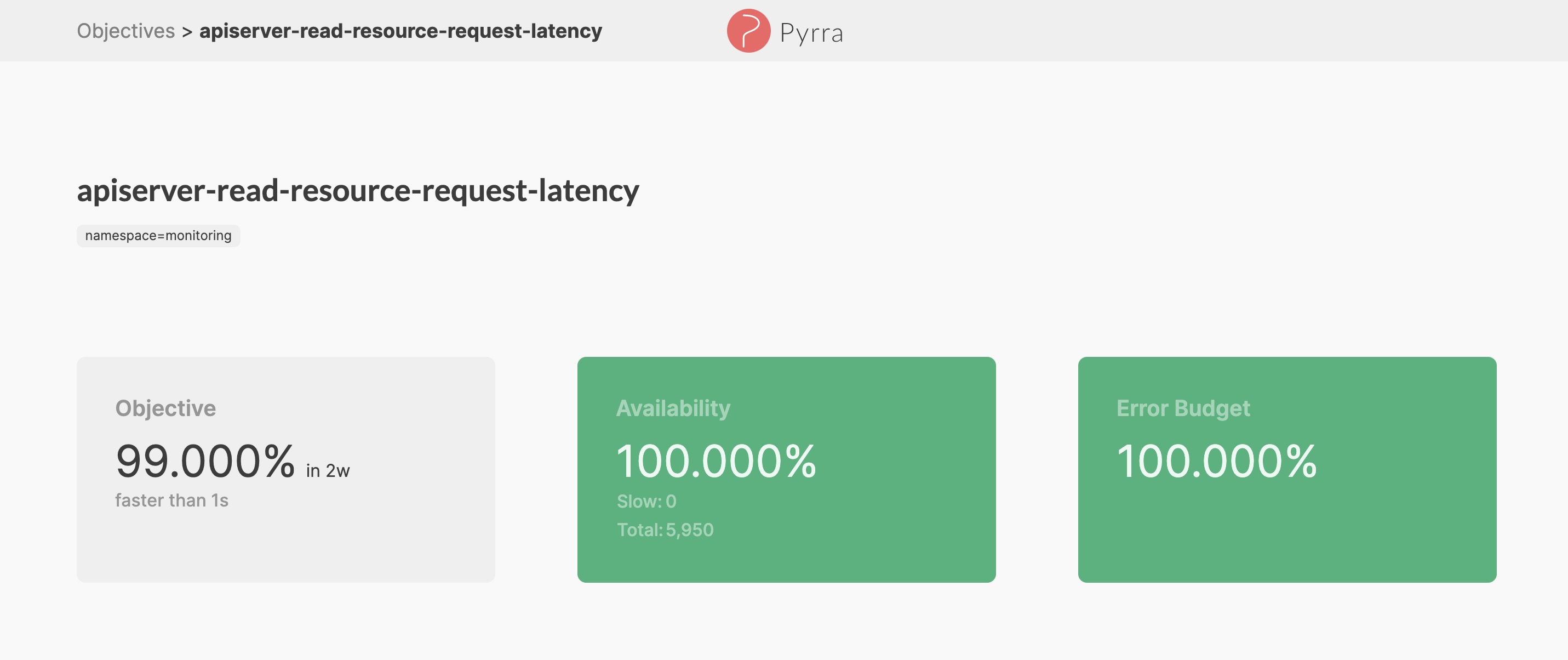
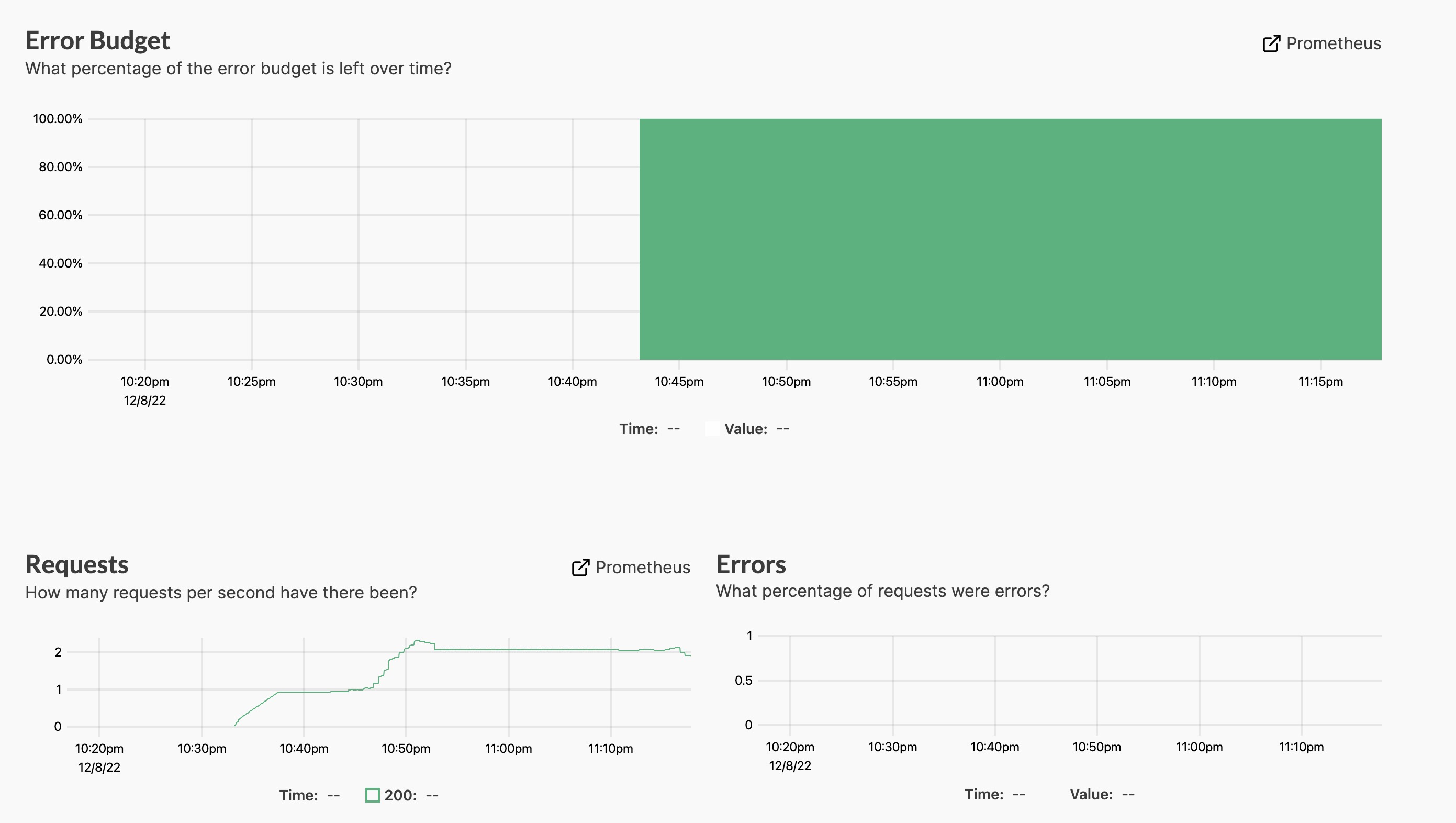
Pyrra 尝试解决了 SLO 的管理问题,但是还有一个问题 Pyrra 无法解决,就是如何定义一个合适的 SLO,当然这并不是一个简单的事情,需要结合实际的业务系统进行针对性的设计。
所以讲者在 talk 对运维一个 k8s 集群的稳定提供了几个 SLO 的建议,值得参考
kubelet:
- 第一个 SLO 是 kubelet-runtime-errors:它是通过原始指标 kubelet_runtime_operations_total,kubelet_runtime_operations_errors_total 计算而成,代表了 kubelet 同底层运行时进行交互的成功率。
- 第二个 SLO 是 kubelet-request-errors:它是通过 rest_client_requests_total 指标计算而成,代表 Kubelet 访问 APIServer 的成功率。
kube-proxy:
- 推荐 SLO 是 kube-proxy-sync-rules-latency:他是通过 kubeproxy_sync_proxy_rules_duration_seconds 指标计算而成,代表了 kube-proxy 同步 service 背后的 pod 变动到节点的速度,如果过慢会导致同步不及时,影响流量的转发。
APIServer:对于 APIServer 来讲,k8s 官方已经为其定定义的 SLO,讲者在这个基础上提供了3个 SLO
- apiserver-read-response-errors:APIServer 读请求成功率
- apiserver-write-response-errors:APIServer 写请求成功率
- apiserver-read-resource-latency:APIServer 读延时
上述所有 SLO 的详细定义,都可以从引用 2 中下载讲者的 PPT,进行详细的查看。
参考
- Talk 1: https://kccncna2022.sched.com/event/182Fz/customer-centric-observability-how-intuit-reduced-time-to-detect-customer-impact-from-30-minutes-to-under-3-minutes-vinit-samel-intuit-nagaraja-tantry-intui?iframe=no&w=100%&sidebar=yes&bg=no
- Talk 2: https://kccncna2022.sched.com/event/182G2/slo-based-observability-for-all-kubernetes-cluster-components-matthias-loibl-polar-signals-nadine-vehling-grafana-labs?iframe=no&w=100%&sidebar=yes&bg=no