0. 一句话总结
本文将介绍 opentelemetry collector 插件集合中的 spanmetrics connector 插件,主要描述它的基本功能和基本使用方式,并且进一步结合 demo 示例展示它的基本使用方法和其他的一些高阶使用方法。
将主要从以下几个问题出发
- 什么是 opentelemetry collector?
- 什么是 connector 类型插件?
- 什么是 spanmetrics connector 插件?
- 如何使用 spanmetrics connector 插件?
1. 什么是 opentelemetry collector?
Opentelemetry 是开源社区针对可观测领域相关技术制定的一套新的技术标准。它出现的目的是为了解决,用户在对自身业务进行可观测能力建设时,最常遇到的两个问题
- 多种多样的可观测数据类型:包括 metric,trace,log,profiling,exception,每种数据类型都有各自的特点,且难以联动
- 多种多样的可观测服务提供商:市面上存在多种可观测服务提供商(比如 datadog)或者开源解决方案(比如 prometheus),但是方案之间数据协议不一致,接入方式不一致,导致用户被服务商强绑定,迁移方案成本很高,并且服务商之间缺乏数据联动。
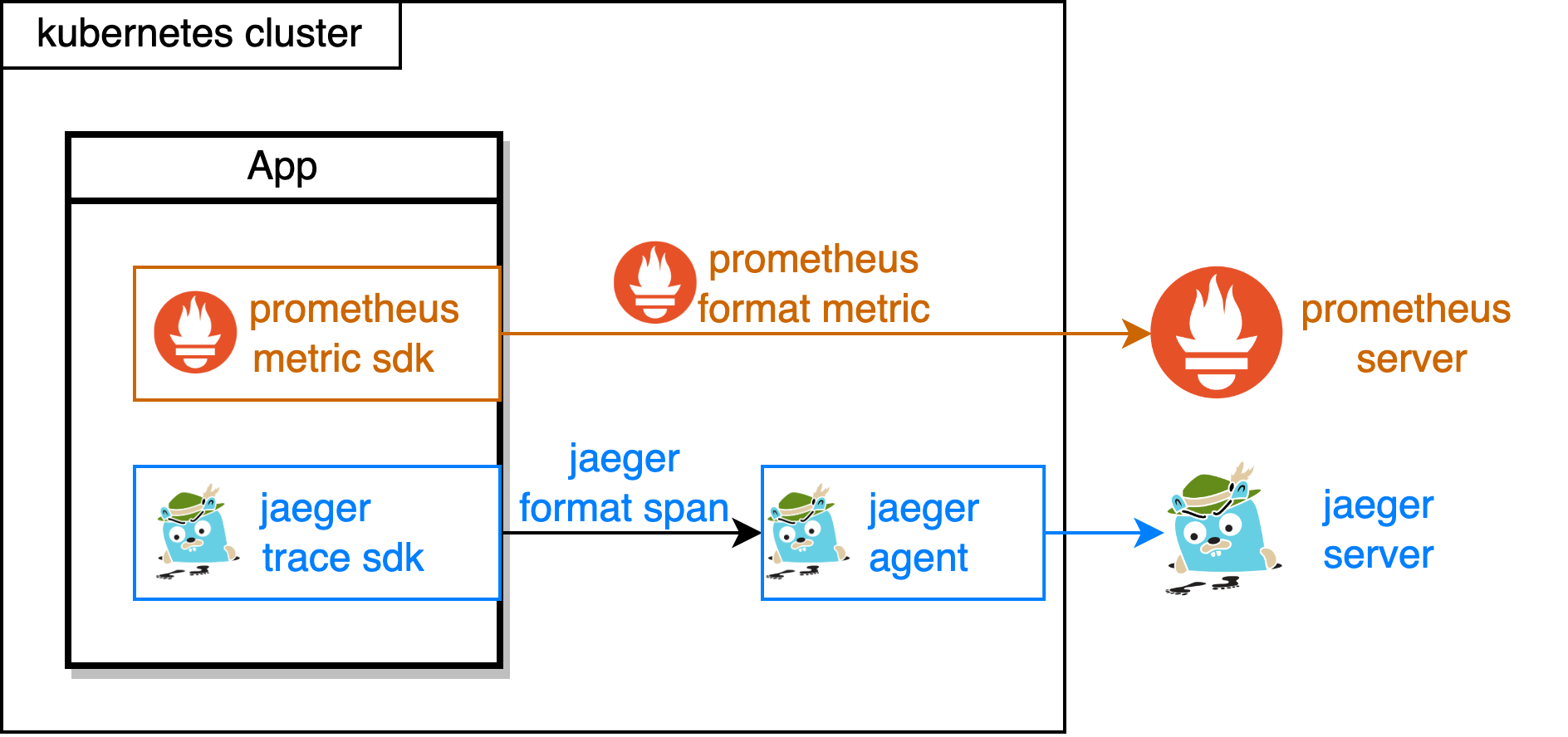
如上图所示,业务程序需要根据自己选择的可观测方案(比如 prometheus,jaeger),用对应的 SDK(prometheus metric sdk,jaeger trace sdk)进行数据埋点,并且需要部署方案对应的采集服务(jaeger agent),最终将数据持久化到对应的存储中(prometheus server, jaeger server)。想要切换解决方案(比如从 jaeger 切换为 zipkin),就需要切换完整的一套。
所以 Opentelemetry 提供了几个方面的能力来解决这些问题:
- 针对常见的可观测数据类型(metric,trace,log,profiling)提供了统一 API 定义:规范了各种数据的格式标准,联动方式
- 针对不同编程语言的提供了数据埋点的 SDK:golang,java,c++,python 等大部分常见语言都以覆盖,用户通过引入 SDK 即可生产标准的可观测数据
- 针对数据采集,处理,导出的需求,提供了一个强大工具 opentelemetry-collector:用户可以通过配置为 collector 内部编排多个从数据的处理流,每个流都包含数据的输入,处理,输出3个阶段。用户可以在其中根据自己的需求对数据进行非常灵活的二次加工,并且最终输出到希望输出的任何存储中。
最终在 Opentelemetry 的加持下,业务的可观测体系变成下面的样子
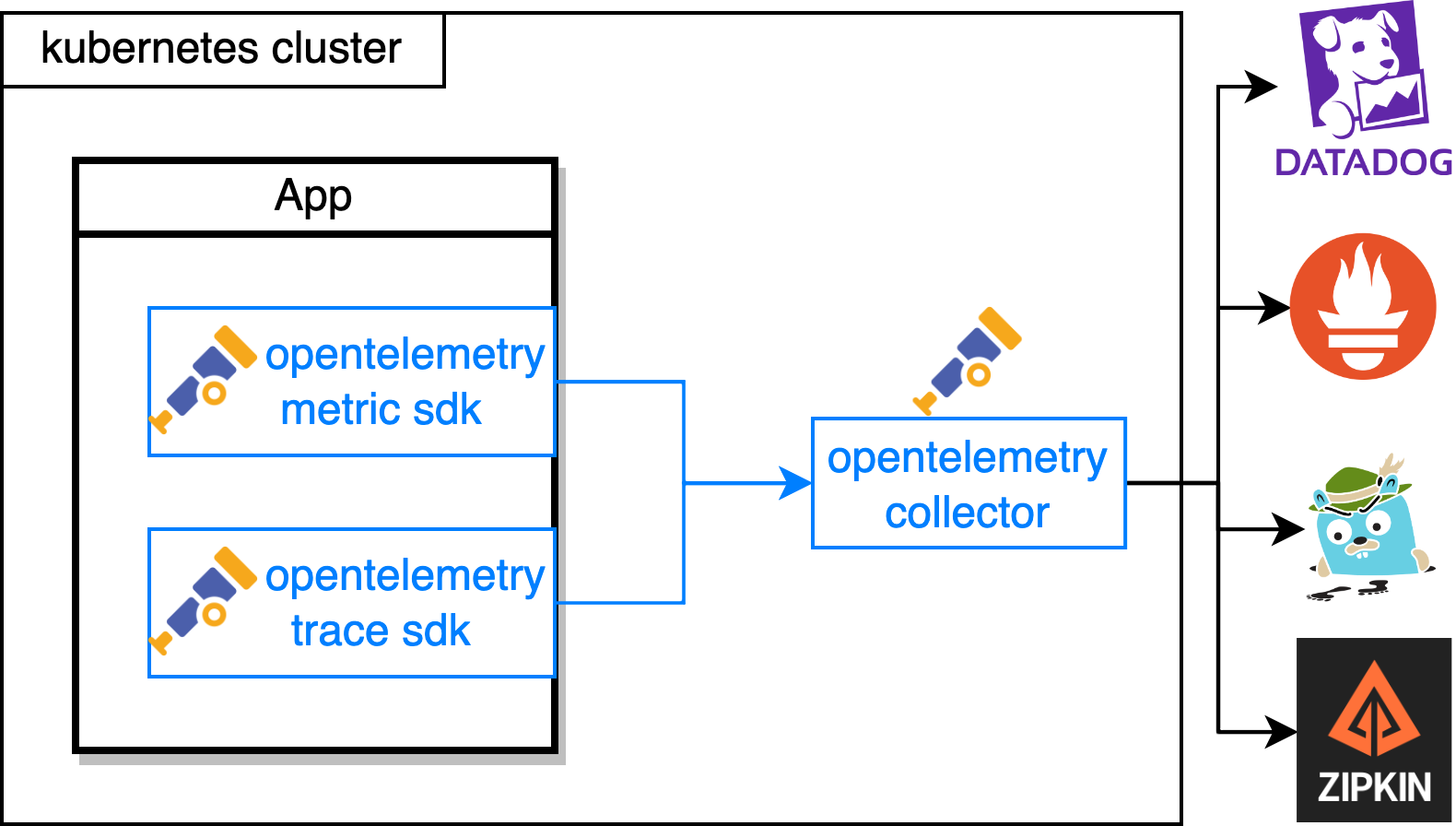
在这种状态下,用户一方面在也不用担心被某个解决方案所绑定,可以随意切换最终的可观测服务商,只要他兼容了 opentelemetry 协议。另一方面用户还可以使用 opentelemetry-collector 强大的数据加工能力,对数据进行灵活的二次处理。
2. 什么是 connector 类型的插件?
我们都知道 opentelemetry collector 是一种插件式架构,可以配置多种插件来收集(receiver)、处理(processor)和导出(exporter)可观测数据,形成一个个可观测数据的处理流(pipeline)。
但是在这套架构下,每个数据流(pipeline)之间都是彼此比较独立的,无法进行进一步的组合,串联,形成更加复杂的 pipeline。
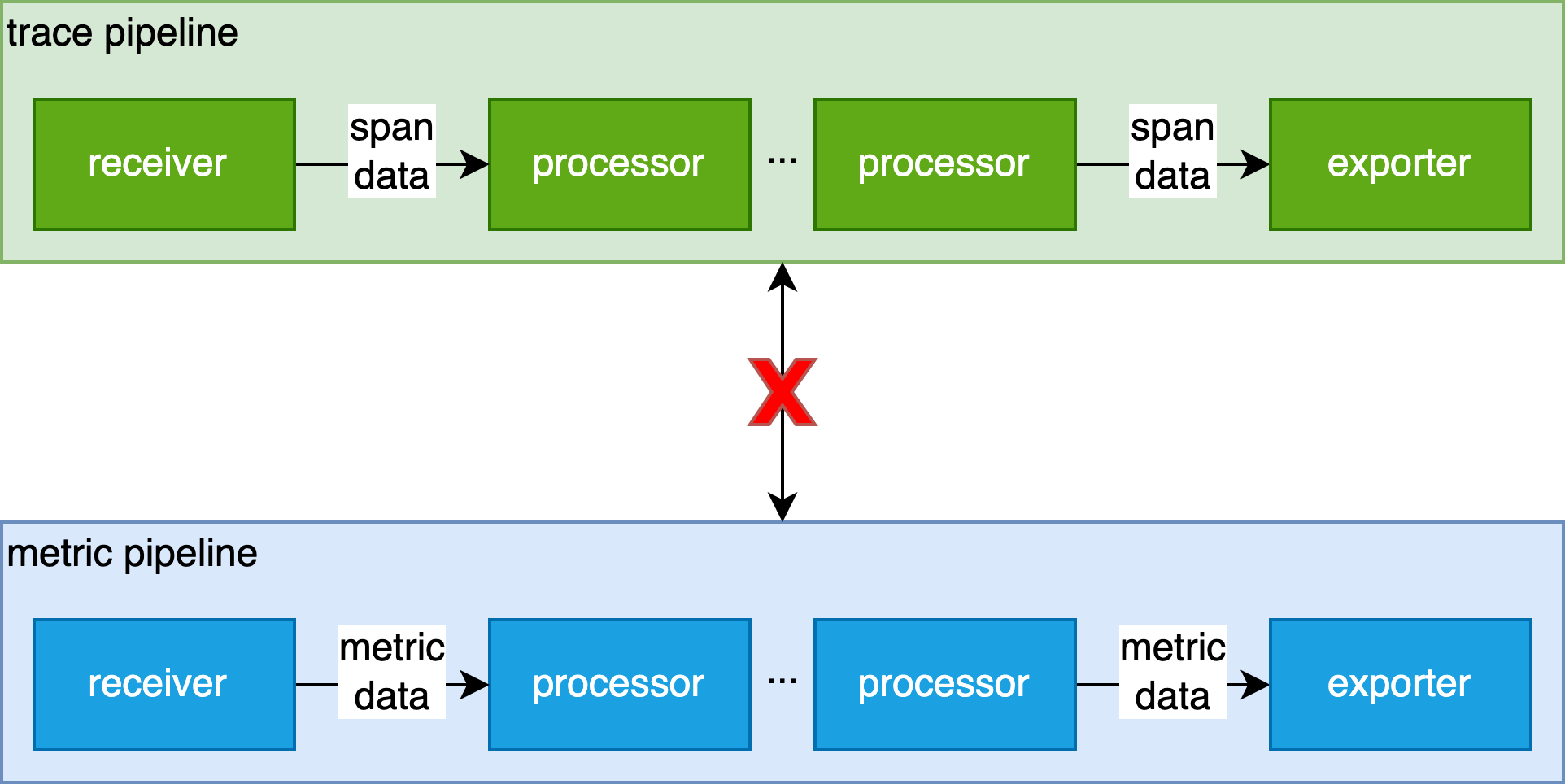
这种限制使一些需求无法被很好的满足。比如我们如果想从 trace pipeline export 出来的 span 数据中二次统计出有价值的 metrics 数据再导出到一个 metric 的 pipeline 中。
所以社区在 issue 中第一次提出了一种新的插件类型 —— connector,可以满足这种,需要将不同的 pipeline 进行串联组合的需求。
Connector 的实现思路是,它将作为一个桥梁,同时以 receiver,exporter 的角色编排到不同的 pipeline 中,从而多个 pipeline 之间的串联,形成一个更加复杂的 pipeline。其中串联的 pipeline 甚至可以是处理不同类型的数据的 pipeline,比如将 trace pipeline 和 metric pipeline 串联起来。

正如上图所示,connector 变成了一个桥梁,将原本无法串联起来的 trace pipeline 和 metric pipeline 串联起来了。而对应的配置文件会变成下面的样子
receivers:
otlp:
exporters:
prometheus:
connectors:
count:
service:
pipelines:
traces:
receivers: [otlp]
exporters: [count]
metrics:
receivers: [count]
exporters: [prometheus]
从配置文件中,可以发现,我们首先定义一个 count 类型的 connector 插件,而后针对这个 connector,我们
- 一方面把这个 count connector 作为 trace 类型的 pipeline 的 exporter,并且 connector 会把得到的 span 转换为 metric;
- 另一方面把这个 count connector 作为 metric 类型的 pipeline 的 receiver,从而最终输出给 prometheus exporter。
也就是说,connector 在内部完成了从 trace 到 metric 数据的转换工作,从而把原本无法关联的两个 trace 和 metric pipeline 很好的串联起来。
目前 connectors 这种插件类型的已经开发完成,而且它有几种典型的场景所需要的 connector 插件也都已经实现。
多 pipeline 组合场景 —— forward connector: 专门用于将多个 pipeline 的输出合并起来统一输出给另一个 pipeline,也可用来将单个 pipeline 数据流导出到多份其他 pipeline 进行不同诉求的2次处理。
数据类型转换场景 —— count connector: 专门用于统计各种可观测数据原始数据量的 connector,比如 span 的总数,metric 总数,metrics 中 datapoint 总数;并且把数量转换为 metric 指标。
而 spanmetrics connector 就是我们这次要重点介绍的一种 connector。他是属于典型的数据类型转换的场景。
3. 什么是 spanmetrics connector 插件?
Spanmetrics connector 用来解决的问题是 —— 从接受到的 trace 数据中计算出有价值的统计类 R.E.D 指标 —— 请求总数(Request),请求错误数(Error) 和请求响应延时(Duration)。
实际使用时,spanmetric connector 会生产出如下两组 metric
sum 类型指标 —— calls_total:可以用于统计请求的总数(Request);而通过 status.code == error 的过滤条件,可以统计出错误请求总数(Error)。
histogram 类型指标 —— duration_millisecond :即通过 histogram 类型统计的请求延时(Duration)。
而且在默认情况下,spanmetrics connector 会为上述指标自动添加如下几个 label,用于进行更细粒度的统计
- service.name
- span.nam
- span.kind
- status.code
比如 sum by (service_name)(calls_total{status_code == "error"}) 就是在按照服务的粒度统计每个服务的失败请求总数。
4. 怎么使用 spanmetrics connector 插件?
4.1 最基本使用
在当前最新版本下(0.76.1),只需要 2 个步骤
- 在配置文件中,开启 spanmetrics connector
- 在配置文件中的 pipeline 中,加入 spanmetrics connector
- spanmetrics connector 一般会是某个 trace pipeline 的 receiver,某个 metric pipeline 的 exporter
我们可以在 otel 官方的 demo 仓库中看到这个用法,并且直接本地体验一下 spanmetrics 的基本功能。这个 demo 项目模拟了一个电商网站,其中也包含通过多种语言编写的多个微服务。本地体验这个 demo 的方式非常简单,通过如下几个步骤即可
git clone git@github.com:open-telemetry/opentelemetry-demo.git
cd opentelemetry-demo
docker compose up --no-build
等到页面 http://127.0.0.1:8080/ 可以访问后,这套电商系统就启动好了,你可以在其中模仿一个用户做些浏览,加入购物车,购买等操作,构造出一些数据。
而在这个 demo 中,也包括了 otel-collector,prometheus,grafana,jaeger 等可观测性组件。在 grafana 中的大盘中,就包括了通过 spanmetrics connector 生成的指标构造出来的大盘,官方 demo 也提供了基于这些指标构造的大盘。
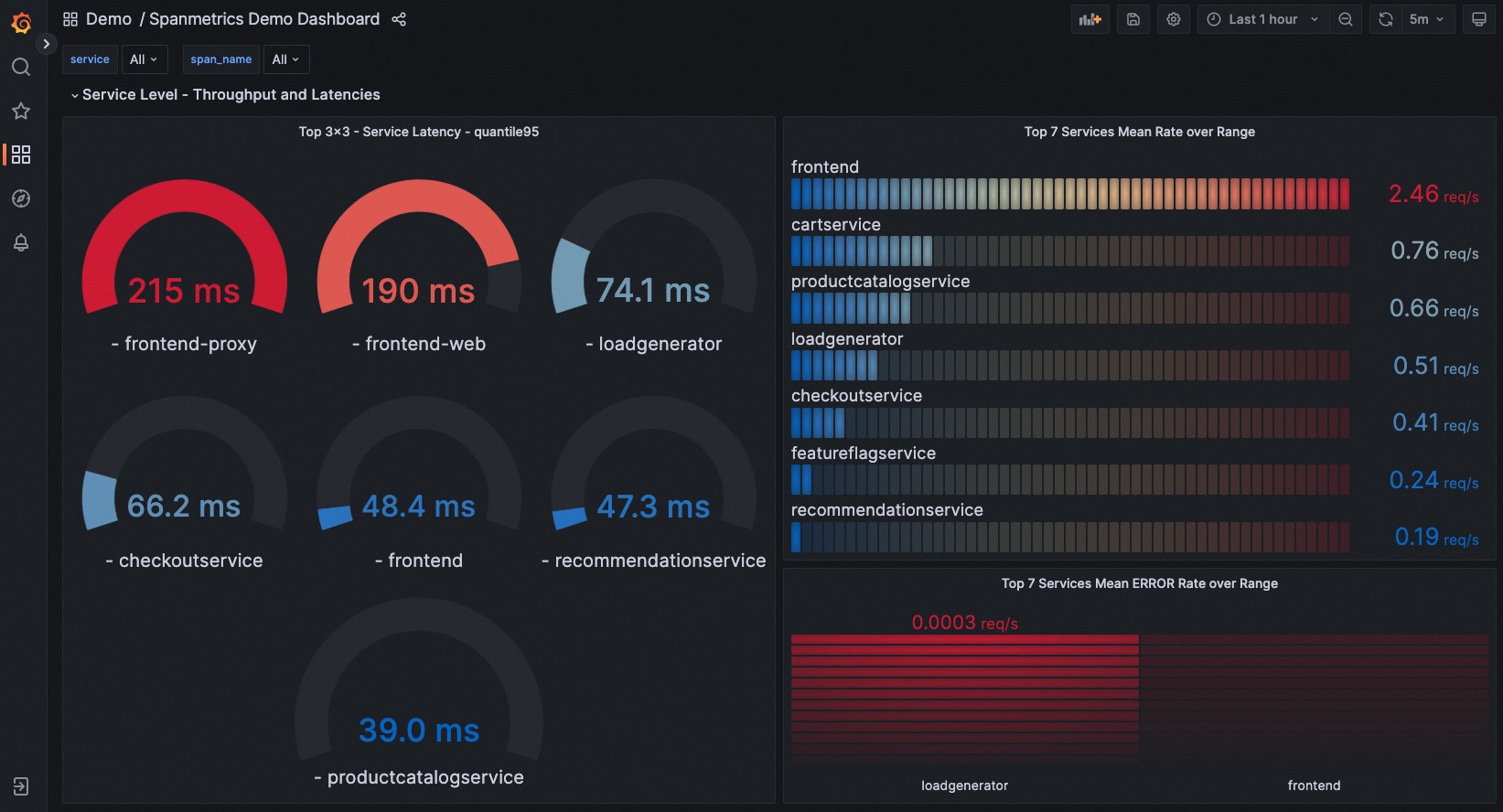
我们可以在这个大盘中看到各种维度的统计
- 每个微服务整体的平均延时,QPS,错误率
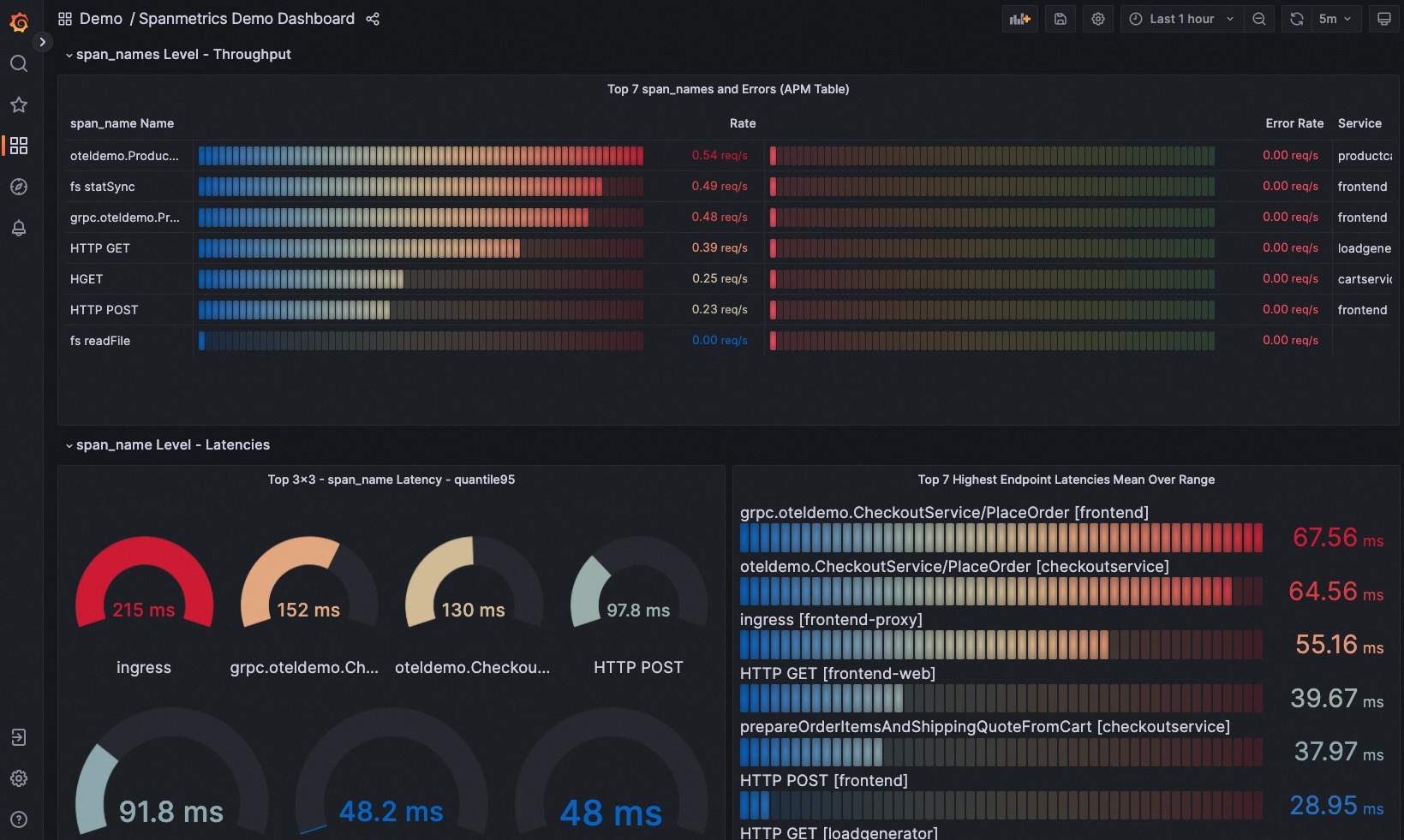
- 每种 span 的平均延时,QPS,错误率
除了基本的默认使用方式,spanmetrics 也提供了几种更高阶的使用模式
4.2 高阶使用 —— 自定义统计维度
除了默认的 4 个 label,用户可以根据自己的需求指定其他的 label 作为新的聚合维度。比如说如果我们是在使用一个 http 协议的服务。那么我们可以通过将配置文件修改为如下形式
connectors:
spanmetrics:
dimensions:
- name: http.method
default: GET
- name: http.status_code
从而为最终的指标增加 http.method, http.status_code 的这两个统计维度,可以更好的针对不同的 http.method, http.status code 进行统计。
4.3 高阶使用 —— exemplar 能力
Exemplar 是一种能够将 metric 和 trace 建立起内在联系的手段。可以让运维人员在通过 metrics 发现线上的潜在问题时,可以通过 exemplar 信息快速定位到引起 metric 指标异常的具体 trace,实现一键根因定位。
想象一个非常常见的日常问题排查的场景:当运维人员发现,某个服务的 p99 延时突然升高时,典型的处理方法就是去查询延时升高的时间段,该服务的日志,是否有记录处理某些请求耗时比较长的日志记录;或者通过 trace 数据,搜索耗时大于某个阈值的所有 trace 信息。无论是哪一种方式,都面临不小的检索工作。而且很有可能这些信息并没有被记录下来,导致问题变成了一个未解之谜。
但是有了 exemplar 能力,我们可以极大的提升这个检索的速度,我们可以快速的定位到引起 metric 指标变成现在这个状态的具体的 trace id,从而可以迅速定位引起问题的具体请求,进而进一步分析根因。
Exemplar 核心设计思想就是,在 metric 上额外附上一种叫做 exemplar 的额外信息,而这个信息比较常见的就是 trace id,下面的这个样例就是 OpenTelemetry 官方定义的 exemplar 格式,我们可以看到,针对 histogram 类型,每个 bucket 上,我们都可以选择附上一个 trace_id 的信息,这个 trace_id 对应的 trace 也是正好位于这个 bucket 的范围内。
# TYPE foo histogram
foo_bucket{le="0.01"} 0
foo_bucket{le="0.1"} 8 # {} 0.054
foo_bucket{le="1"} 11 # {trace_id="KOO5S4vxi0o"} 0.67
foo_bucket{le="10"} 17 # {trace_id="oHg5SJYRHA0"} 9.8 1520879607.789
foo_bucket{le="+Inf"} 17
foo_count 17
foo_sum 324789.3
foo_created 1520430000.123
如果没有 opentelemetry-collector 还想要使用 exemplar 能力,我们需要修改业务代码中有关 metric 埋点部分需要调用的函数,但是这种方式给业务研发带来一定的接入成本,有侵入性。比如下面就是通过 prometheus go client sdk 给 metric 加上 exemplar 信息的方式
handler := http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
starttime := time.Now()
count++
...
ctx := req.Context()
traceId := trace.SpanContextFromContext(ctx).TraceID()
if _, err := w.Write([]byte("world")); err != nil {
http.Error(w, "write operation failed.", http.StatusInternalServerError)
return
}
log.Printf("request use %v seconds\n", float64(time.Since(starttime))/float64(time.Second))
requestDurationsHistogram.(prometheus.ExemplarObserver).ObserveWithExemplar(float64(time.Since(starttime))/float64(time.Second), prometheus.Labels{
"traceID": traceId.String(),
})
})
但是通过 spanmetrics connector 生成的指标,connector 会直接附加上 exemplar 信息,极大降低了研发对 exemplar 的使用成本,无侵入性。
我们可以在官方 demo 中体验这个非常便捷的功能。查看页面 http://127.0.0.1:8080/grafana/d/W2gX2zHVk/demo-dashboard?orgId=1&viewPanel=2&var-service=frontend
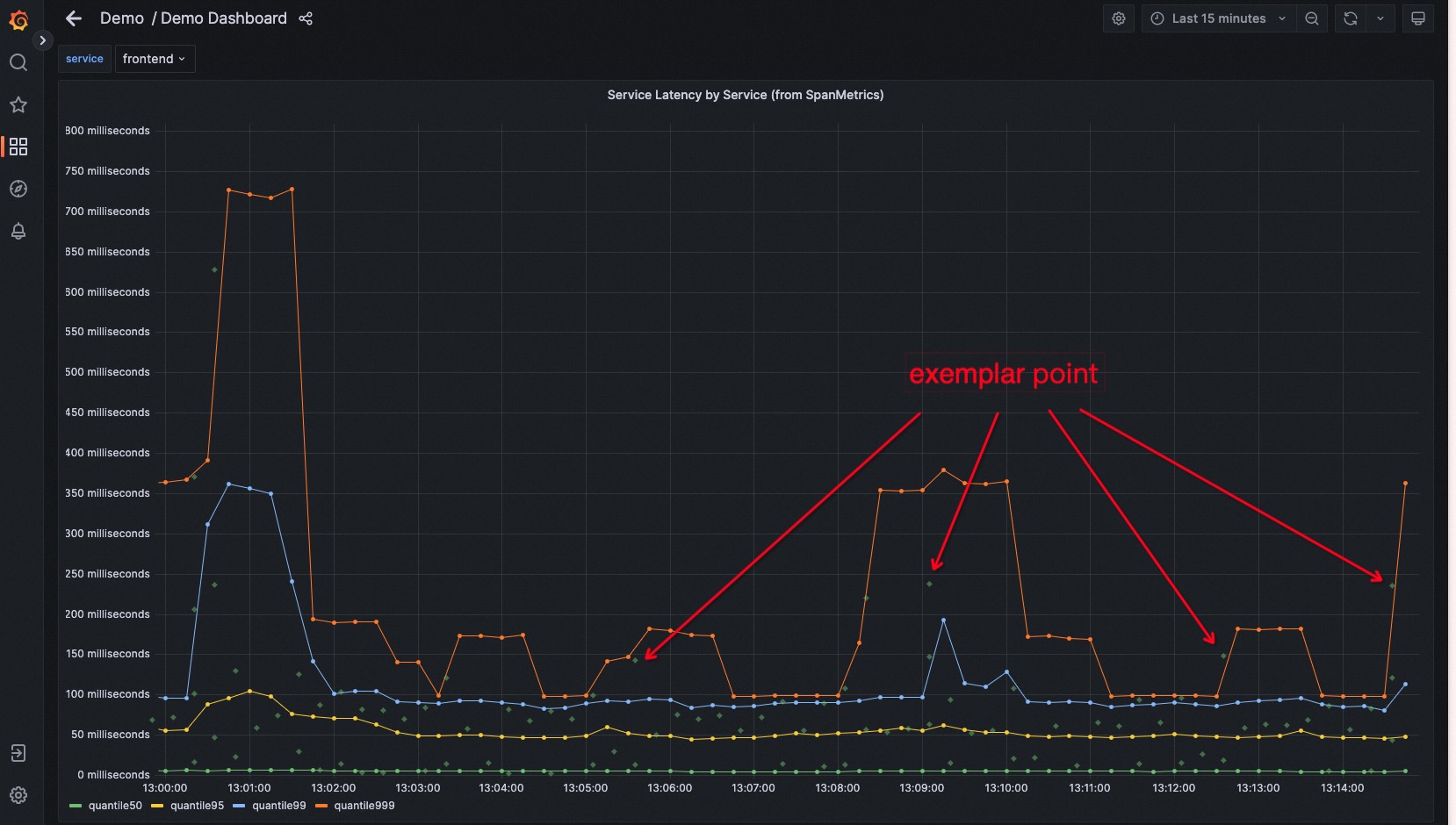
我们可以看到这个页面和前面展示页面的不同点是,它开启了在 dashboard 上展示 exemplar 信息的开关,所以我们可以在页面的每一条 metrics 曲线上看到很多散列的点,这些点就是 exemplar。而这些 exemplar 点所在的位置,就可以理解为这个时间点的 metric 值是基于一组 trace 数据统计的,其中就包括了这个 exemplar 点对应的 trace。
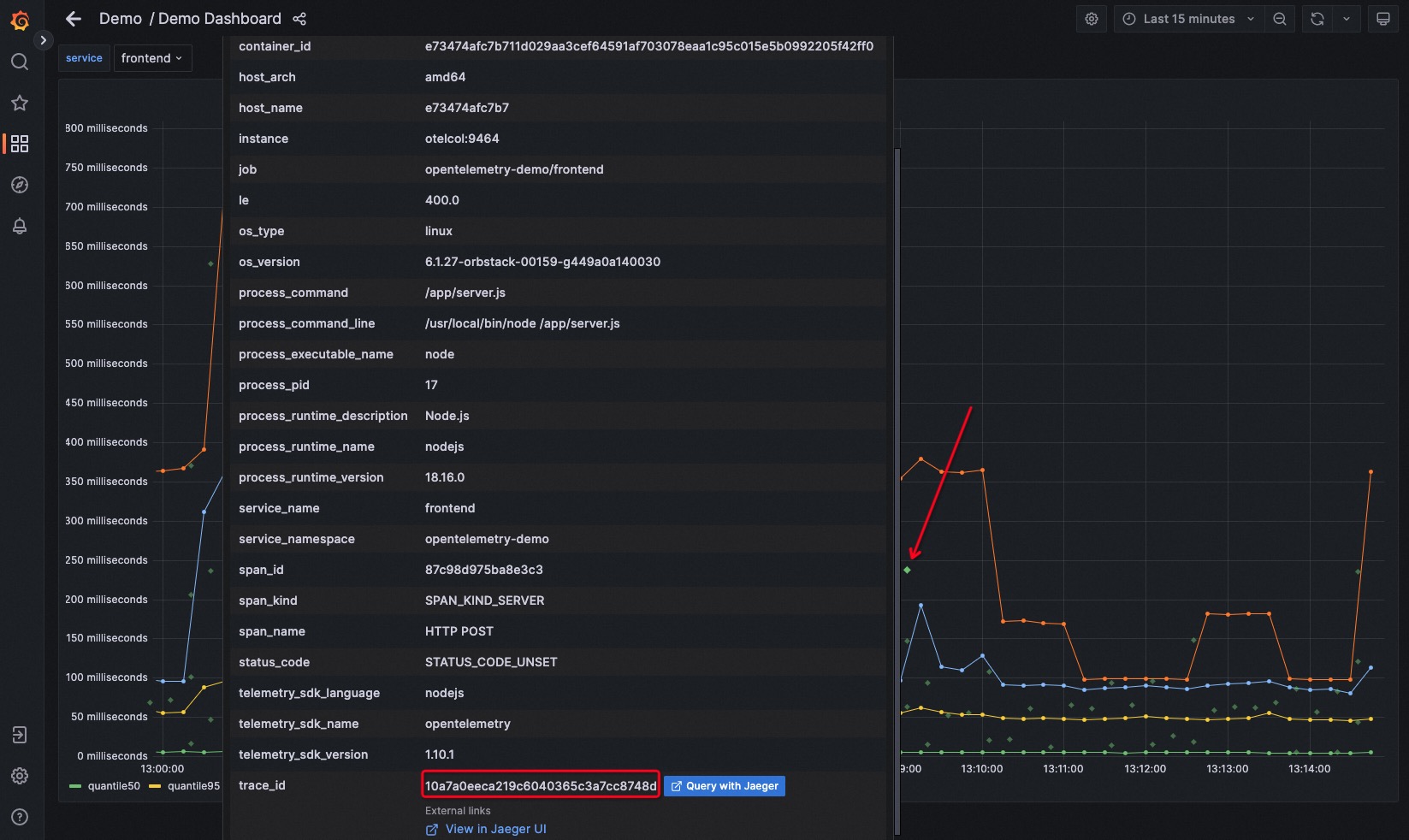
当我们把光标放到任意一个 exemplar 点上时,就会弹出这个 exemplar 点代表的 span 的详细信息,比如 trace id。并且我们可以注意到,这里还有一个 “Query with Jaeger” 的按钮。
点击这个按钮,我们就可以以这个 exemplar 对应的 trace id 查找到具体的 trace 的链路信息,跳转到访问 Jaeger 的页面。
3.4 高阶使用 —— explicit / exponential histogram
通过 spanmetrics 生成 histogram 类型的指标 duration_millisecond 时,在默认配置下,spanmetrics connector 使用的 histogram 类型是 explicit histogram。但是除此之外,我们也可以选择让 spanmetrics connector 使用相比于默认的 explicit histogram 更强大一种 histogram 类型 —— exponential histogram。
什么是 explicit histogram?
Explicit histogram 是现如今被广泛使用的一种 histogram 类型,包括 prometheus 官方默认支持的也是 explicit histogram,它的典型特点是用户需要自定义每一个 bucket 的区间(当然如果不指定的话,SDK 一般也会默认给定一组 bucket 区间)。
在 spanmetrics connector 中也可以进一步由用户指定具体的 bucket 区间。指定方式如下
connectors:
spanmetrics:
histogram:
explicit:
buckets: [ 10ms, 100ms, 250ms ]
在上面的配置中,指定了 0-10ms,10ms-100ms,100-250ms,250ms~+inf 四个区间。
explicit histogram 虽然已经被广泛使用,但是这种格式一直有几个问题没有解决
- bucket 区间指定很难准确:如果对系统的情况不了解,很难给出准确的 bucket 区间分布,导致很有可能所有数据都落在某个区间里面,整体非常难以描述数据本身的特点。
- bucket 改动成本高,无法动态调整:bucket 一旦指定,如果想改变,只能通过重新编写代码,重启服务,导致历史数据也无法复用
- 存储成本高:因为用户可以随意指定,没有固定规律。所以每个 bucket 的区间左右边界都需要独立存储,整体的存储成本就是所有 bucket 的边界值,和每个 bucket 的计数。
所以一种新的 histogram 类型 exponential histogram 出现了。
什么是 exponential histogram 呢?
exponential histogram 是 otel 社区提出的一种更高精度,存储更高效的 histogram 指标类型。它和 explicit histogram 相比最核心的差别在于,在 exponential histogram 中,bucket 的区间边界是有规律的。
假设某个 histogram 总共有 n 个 bucket,某个编号为 i 的 bucket 的左右边界就是 base^i 和 base^(i+1)。而其中的 base 是通过如下算式确定
base = 2^2^(-scale)
可见整个 exponential histogram 的所有 bucket 区间,我们通过 2 个参数即可确认,一个 bucket 总数 n;另一个就是 scale,他控制了每个 bucket 的大小。所以通过 scale 其实我们控制的是这个 histogram 可以表示的 bucket 的精度,scale 的值越大,bucket 的控制的区间就越小,数值也就越精细越准确。比如,当 scale 为 -1 时,base 为 4,第 0 个 bucket 的区间为 (0, 4); 当 scale 为 0 时,base 为 2,第 0 个 bucket 的区间为 (0, 2),第 1 个 bucket 的区间为 (2,4)。可见在 scale 变大时,bucket 区间被拆分为更细的大小了。
相比于 explicit histogram,exponential histogram 的优势在于
- 使用更友好
但是 exponential histogram 就不用,你无需提前指定 boundaries,在 exponential histogram 中,所有 bucket 的边界都有它的规律。只要知道关键参数就可以全部计算出来。
- 数据精度更高
exponential histogram 这种指数化的表示方式,特别适合表示日常非常常见的长尾分布情况。比如 http server 的请求延时情况,响应请求大小情况,都是非常典型的长尾分布情况,可以尽可能的减少 histogram 这种统计方式带来的数据误差。
- 存储效率更高
对于 explicit histogram 来说,存储 N 个 bucket 值的,需要同时存储 bucket 边界,和 bucket 计数两部分信息,整体开销是 2N。
而 exponential histogram 来说,只要知道 base 和 bucket 总数,既可以复原出所有 bucket 边界值,所以整体的开销是 N。
目前 exponential histogram 的数据类型定义已经合并到 opentelemetry 官方库中。并且有很些第三方的可观测厂商已经支持了对 exponential histogram 数据类型的输入,比如 New Relic。
而开源社区中,prometheus 目前已经开放了一个叫做 native histogram 的实验 feature,它背后其实同 exponential histogram 采取的是相同的思路,只不过在代码实现上稍微有些不同。Prometheus 的维护者在今年的 Observability Day 详细介绍了 exponential histogram 和 native histogram 之间的设计差别。并且也在 prometheusremotewriteexporter 中支持了将 exponential histogram 转换为 native histogram 的能力。所以我们很自然的就可以想到,如果我们将 spanmetrics connector 生成的 exponential histogram 通过 prometheusremotewriteexporter 导入到 prometheus 中,我们不就实现了在 prometheus 中消费 spanmetrics connector 构造的 exponential histogram 数据了吗?
但是实际情况是,目前还不能做到,主要有一个问题在于 spanmetrics connector 中采用的是 lightstep 提供的 exponential histogram 库构造的 histogram 数据,这个库默认提供的精度参数scale 是 20,远远高于 prometheus 目前接受的最高精度 8,所以在输出到 prometheus 时会被拒绝。所以社区也将这个问题跟踪,相信很快就会得到解决。
参考
- https://newrelic.com/blog/best-practices/opentelemetry-histograms
- https://github.com/open-telemetry/opentelemetry-collector/tree/main/connector
- https://github.com/open-telemetry/opentelemetry-collector/issues/2336
- https://github.com/open-telemetry/opentelemetry-collector/tree/main/connector/forwardconnector
- https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/connector/countconnector
- https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/connector/spanmetricsconnector
- https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/data-model.md#exponentialhistogram
- https://github.com/open-telemetry/oteps/blob/main/text/0149-exponential-histogram.md
- https://prometheus.io/docs/prometheus/latest/feature_flags/#native-histograms
- https://github.com/open-telemetry/opentelemetry-collector-contrib/pull/17370
- https://www.youtube.com/watch?v=W2_TpDcess8